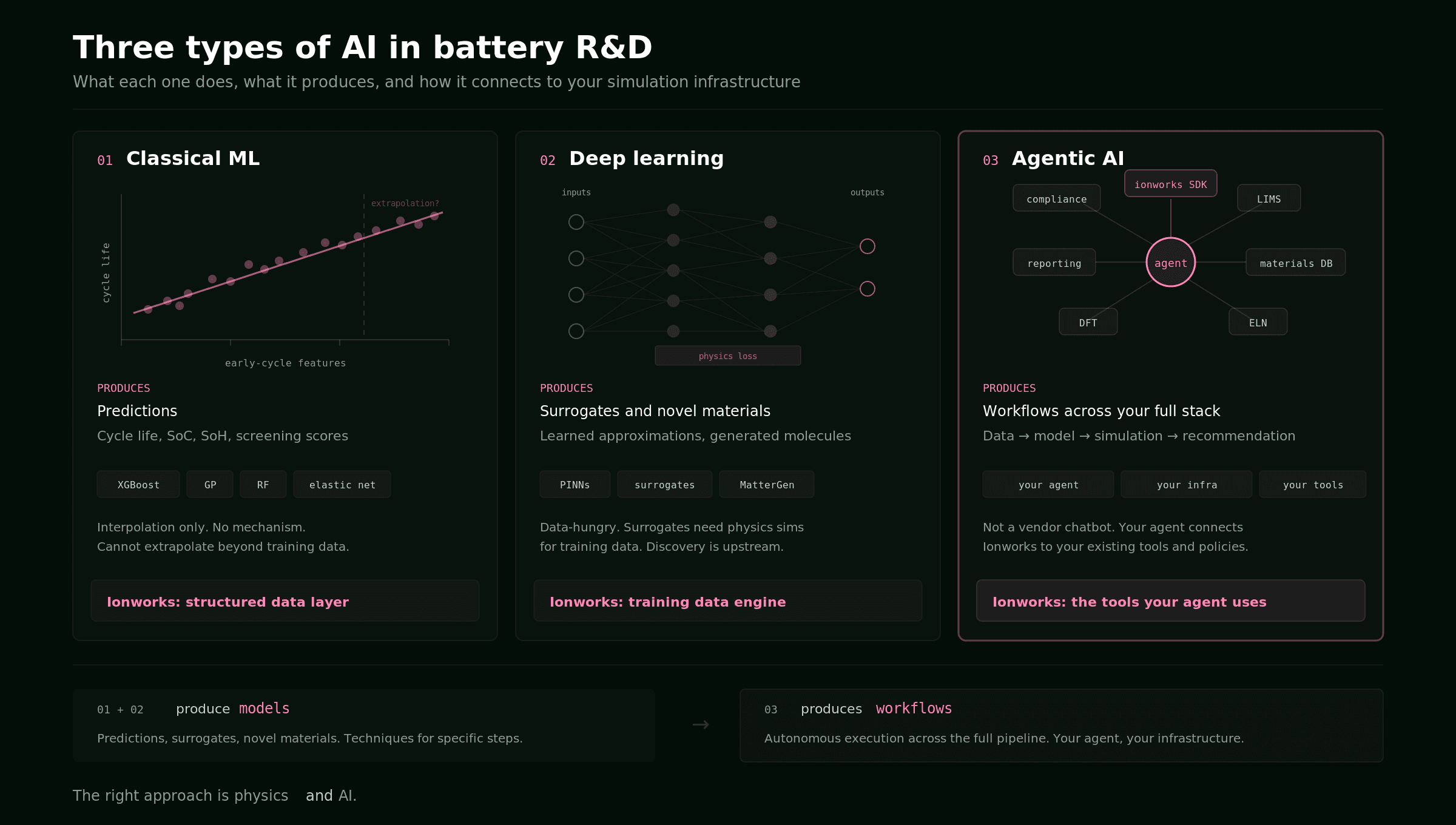
Every battery R&D organization is being told to "use AI." The mandate comes from leadership, from investors, from the competitive pressure of watching other teams move faster. But "use AI" is not a strategy. It is a direction without a map.
The problem is that AI in battery engineering is not one thing. A cell engineer asking ChatGPT about formation protocols is using AI. So is a team that has an autonomous agent running parameterization sweeps against their structured cell database while they sleep. These are not the same activity, and they require completely different infrastructure.
This guide introduces four levels of AI integration for battery R&D teams. The levels describe not what AI technique you use (we covered that in our guide to the three types of AI in battery R&D), but how deeply AI connects to your actual engineering data and workflow. The distinction matters because a team's AI level is not determined by which model they have access to. It is determined by the infrastructure underneath.
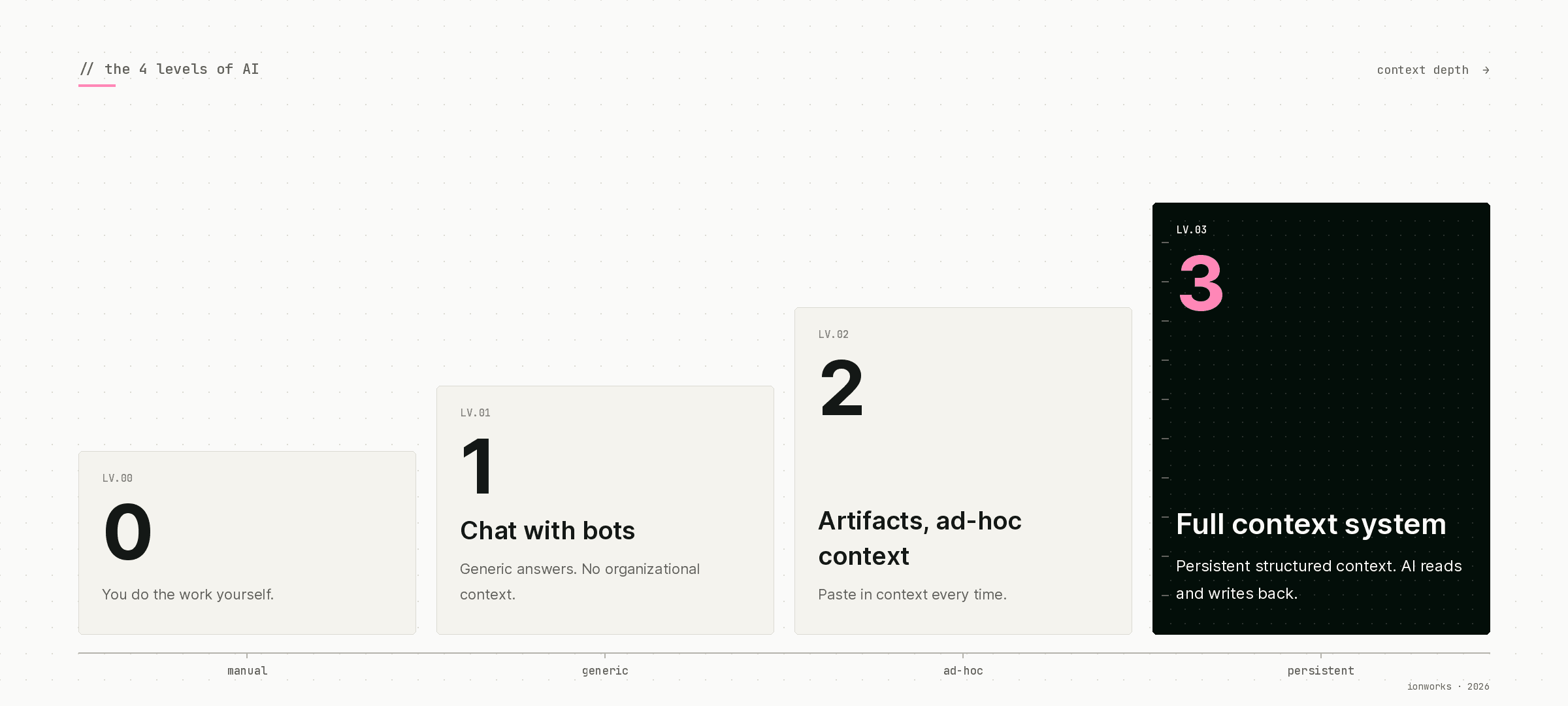
The four levels
Level 0: No AI
The team does not use AI for lab work. Analysis is manual: CSVs opened in Excel or one-off Jupyter notebooks, results communicated via slides and email. Parameterization is done by hand or with custom scripts that one person maintains.
This is still the majority of battery R&D teams in 2026. It is not a failure. Many teams produce excellent work at Level 0. The cost is speed and scalability. Everything depends on the availability and memory of individual engineers.
Level 1: Chat with bots
People on the team ask ChatGPT, Claude, or Gemini general battery questions. "What's a good C-rate for formation of NMC811 pouch cells?" "How do I set up a GITT experiment?" "What does this impedance spectrum tell me?"
The AI gives reasonable answers because it has been trained on the published literature. But it has no knowledge of your cells, your protocols, your test conditions, or your prior results. Every answer is generic. Ask it about your specific NMC811 cells cycled at 2C at 45 degrees C and it gives you textbook NMC811 information, not information about your cells.
Level 1 is useful. It replaces some literature searches and gives junior engineers a fast reference. But it does not change the workflow. The AI is a search engine with better prose.
Level 2: Artifacts with ad-hoc context
This is where most AI-forward battery teams sit today. Engineers paste data into Claude Opus 4.7 or GPT-5.5, upload a cycling CSV, or copy a protocol description, and ask the AI to analyze, summarize, compare, or draft. The output is often good because the human is loading the right context manually.
A typical Level 2 interaction: an engineer exports a capacity fade curve from their Maccor data, pastes it into Claude with the cell spec and test conditions, and asks for a degradation mode analysis. Claude identifies the signature of LLI vs LAM based on the shape of the curve and the rate of fade. The analysis is specific and useful.
The limitation is that every interaction starts from scratch. The context is loaded manually each time. The AI does not remember the analysis it did last week. It cannot pull in the parameter fit from the same cell type tested three months ago. It cannot compare this result to the 40 other NMC811 cells in the database because it does not know the database exists.
Level 2 produces useful artifacts (analyses, summaries, draft protocols) but each one is a standalone effort. Nothing compounds.
Level 3: Full-context system
AI agents operate against structured, persistent data. They can query your cell database, pull prior test results, compare parameter fits, reference historical protocols, and update records. The key word is "your." The AI is working with your lab's specific data, not generic battery knowledge.
A Level 3 interaction looks different. The engineer says: "Compare the degradation behavior of our last three NMC811 batches from Supplier A at 1C and 2C. Flag any batch that shows accelerated capacity fade relative to the baseline parameter set." The agent queries the measurement database, pulls the relevant cycling data, loads the parameterized models, runs the comparison, identifies that Batch 7 shows anomalous SEI growth at 2C, and returns a summary with the supporting data and plots. It files the analysis in the study record so the next person (or the next agent) can build on it.
No one pasted a CSV. No one specified which cells or which parameter sets. The system held the context. The agent knew where to look because the data infrastructure told it.
This is where AI starts to compound. Every analysis the agent runs adds to the structured record. Every parameterization result is linked to its training data. Every protocol is connected to the results it produced. The system gets more valuable with each use, and the agent gets more capable because it has more context to draw on.
What determines your level
The gap between Level 2 and Level 3 is not about AI capability. GPT-5.5 and Claude Opus 4.7 are powerful enough for Level 3 work right now. In fact, once the data is structured, you often do not need the largest model: a faster, cheaper model like Claude Haiku 4.5 can return the right answer because the context already disambiguates the question. The gap is infrastructure. Six dimensions determine whether your lab can support full-context AI.
1. Data capture
How does cycling and test data get from instruments to people?
At the low end, files live on the cycler PC. Someone copies them to a shared drive when asked. At the high end, data is ingested into a structured system automatically. Every measurement links to its cell, protocol, and experimental context. Multiple cycler formats (Maccor, Neware, BioLogic, Arbin, Novonix) are normalized on ingest.
The difference matters because an agent cannot query data that is not in a queryable system. If your Neware files sit in nested folders on a network drive with filenames like Cell_23_test_v2_final_FINAL.csv, no AI model will help.
2. Metadata and traceability
Can you trace a result back to exactly how it was produced?
This is the dimension most teams underestimate. Cycling data without metadata (cell chemistry, formation history, test conditions, equipment serial numbers) is ambiguous. Two identical voltage curves from different cells at different temperatures mean completely different things. An agent that cannot access this context will produce analyses that look plausible but are wrong in ways that matter.
The target state: a query like "show me all NMC811 cells tested above 2C at 45 degrees C" returns results without any human assembly. Cell identity, protocol, chemistry, formation history, and results are linked in a single system.
3. Protocols and experiment design
How are experiments specified and shared?
At Level 0, protocols are verbal instructions or emails. At Level 3, they are structured, machine-readable definitions linked to the cells they were run on and the results they produced. An agent can generate a new protocol variant from natural language ("run the same GITT as last time but at 35 degrees C instead of 25") because it can read the existing protocol definition.
This dimension is often the first one where teams see the value of structure. A parameterized protocol template that an agent can read and modify is worth more than a hundred SOPs in a shared drive.
4. Knowledge management
Where does institutional knowledge live?
Every battery lab has a person who holds it all together. They remember which formation protocol worked for the last NMC batch, which parameter set was validated against the 45-degree data, why the team stopped using Supplier B. When that person is on vacation, work slows down. When they leave, knowledge leaves with them.
Level 3 requires that knowledge be structured and machine-readable. Not a wiki that gets updated sporadically. A system where an agent can look up "what protocol does this team use for GITT on pouch cells" and get a usable answer. Knowledge that gets updated as a side effect of doing work, not as a separate documentation task.
5. Analysis and modeling
How do results become engineering decisions?
The progression runs from manual (open CSVs, plot, write a summary) through shared scripts and notebooks to parameterized models linked to their training data and validation results. At Level 3, an agent can run a parameter sweep, compare to prior fits, and flag anomalies without manual setup. The models have provenance. You can trace any prediction back to the data that trained it and the validation that approved it.
6. The connective layer
Is there a system that ties it all together, or a person?
This is the dimension that separates teams that can adopt agentic AI from teams that cannot. If a single engineer is the glue holding instruments, data, models, and knowledge together, the lab's throughput is bounded by that person's calendar. If a structured engineering layer connects everything, new team members and AI agents can operate effectively from day one.
The connective layer is not a dashboard. It is the persistent, structured context that makes all the other dimensions work together. It is what turns six separate data stores into one system that an agent can reason over.
Scoring your team
Each dimension scores 0 to 3. The total (max 18) maps to an AI readiness tier.
0 to 5: Pre-AI. Your lab would get generic output from any AI tool. The bottleneck is data structure, not AI capability. The first investment should be data capture and metadata, not AI features.
6 to 9: AI-curious. You are using AI for ad-hoc help, but the context is not there for it to be specific to your lab. Structure is the bottleneck, not intelligence. Focus on connecting existing data into a single structured system.
10 to 13: AI-ready in pockets. Some workflows are structured enough for AI to add real value. The gap is connecting them into one system. This is where the connective layer matters most.
14 to 18: Strong foundation. AI agents can operate with deep, specific knowledge of your cells, protocols, and history. This is where compounding starts. Every analysis the system runs makes the next one better.
The pattern across every team we talk to is the same: the bottleneck is never the AI model. It is the structured engineering layer underneath it. Without that layer, AI gives you generic battery answers. With it, AI gives you answers about your cells, your protocols, your data.
The Volta Foundation Battery Report 2025 reached the same conclusion. Their finding: "Efficient battery data management emerges as a key differentiator because it is a hard requirement to enable AI in downstream processes." The report now treats software and data infrastructure as a top-level section alongside cell design and manufacturing. The industry has figured out that the constraint moved from test throughput to data quality.
Moving up: what actually works
From Level 0 to Level 1
This one is free. Give your team access to a frontier chat assistant (Claude, ChatGPT, Gemini, Copilot, or whichever they prefer) and let them use it for reference questions. The value is modest but real: faster literature lookups, better-written reports, a second opinion on experimental design. No infrastructure change required.
From Level 1 to Level 2
Encourage engineers to bring their data to AI interactions. Export cycling data, paste protocol descriptions, upload parameter sets. The analysis quality improves immediately because the AI has specific context instead of generic training knowledge.
The risk at this stage is that teams mistake Level 2 productivity for Level 3 capability. Level 2 feels like AI is working. And it is, for single interactions. But nothing persists. The engineer who did the analysis yesterday has to reload all the same context today. Every new question starts cold.
From Level 2 to Level 3
This is the hard transition, and it is entirely an infrastructure problem. The team needs to go from ad-hoc data loading to a persistent structured layer that agents can read from and write to. That means deploying a system that handles data capture from multiple cycler formats, links measurements to cell specs and protocols, stores parameterized models with provenance, and exposes all of it through an API that agents can call.
Ionworks Studio is built for this transition. Measure handles the data capture and normalization. Train handles parameterization with provenance. Predict runs design sweeps. Optimize handles multi-objective protocol optimization. The API and Python SDK are the connective layer that agents use to operate the full workflow.
The transition does not have to be all-or-nothing. Most teams start with data capture (get cycling data into a structured system) and build outward. Data capture alone moves the score on two dimensions. Adding parameterization with provenance moves two more. Within three to six months, a team that was at Level 1 can have pockets of Level 3 capability in their most important workflows.
Why this matters now
Two forces are converging.
First, battery R&D teams are being asked to cover more chemistries with fewer people. The Volta report documents the trend: LFP dominates global demand, sodium-ion is shipping, solid-state pilot lines are running at six OEMs, silicon anodes are in production timelines. Each chemistry needs fresh parameter sets. Each parameter set requires combining multiple experiments to overcome identifiability constraints. Teams that cannot parameterize fast will fall behind on chemistry evaluation.
Second, AI agent capabilities are improving on a quarterly cadence. The models available today can already handle complex multi-step battery engineering workflows when given proper tool access and structured data. The teams that build the infrastructure now will be ready when agent capabilities take the next step. The teams that wait will be building infrastructure while their competitors are running agents.
The infrastructure is the moat. Not the AI model. The model is a commodity. The structured data, the linked metadata, the parameterized models with provenance: those are specific to your lab, your chemistries, your test conditions. No one else has them. And once an agent is operating against that structured foundation, the value compounds every week.
Score your team
We built an interactive self-assessment that scores your team on all six dimensions and shows you exactly where the gaps are. Takes about three minutes. Your results include a radar chart of the six dimensions, your overall AI readiness tier, and the single dimension that is your biggest bottleneck.
Frequently asked questions
Continue reading