"AI for batteries" has become a category so broad it's nearly meaningless. A random forest predicting cycle life from early voltage curves has nothing in common with a generative model proposing novel electrolyte molecules, and neither of those has much to do with an LLM that can operate a simulation platform through an API. Lumping them together leads to confused purchasing decisions, misaligned expectations, and vendor claims that don't map to any real engineering workflow.
This guide separates the three types of AI that actually matter for battery R&D teams today, describes what each one is good at, and identifies where each one falls short. The goal is practical: if your team is evaluating where AI fits in your workflow, this should help you allocate effort and budget to the right category. For a companion view focused on integration depth rather than technique, see the four levels of AI in battery R&D.
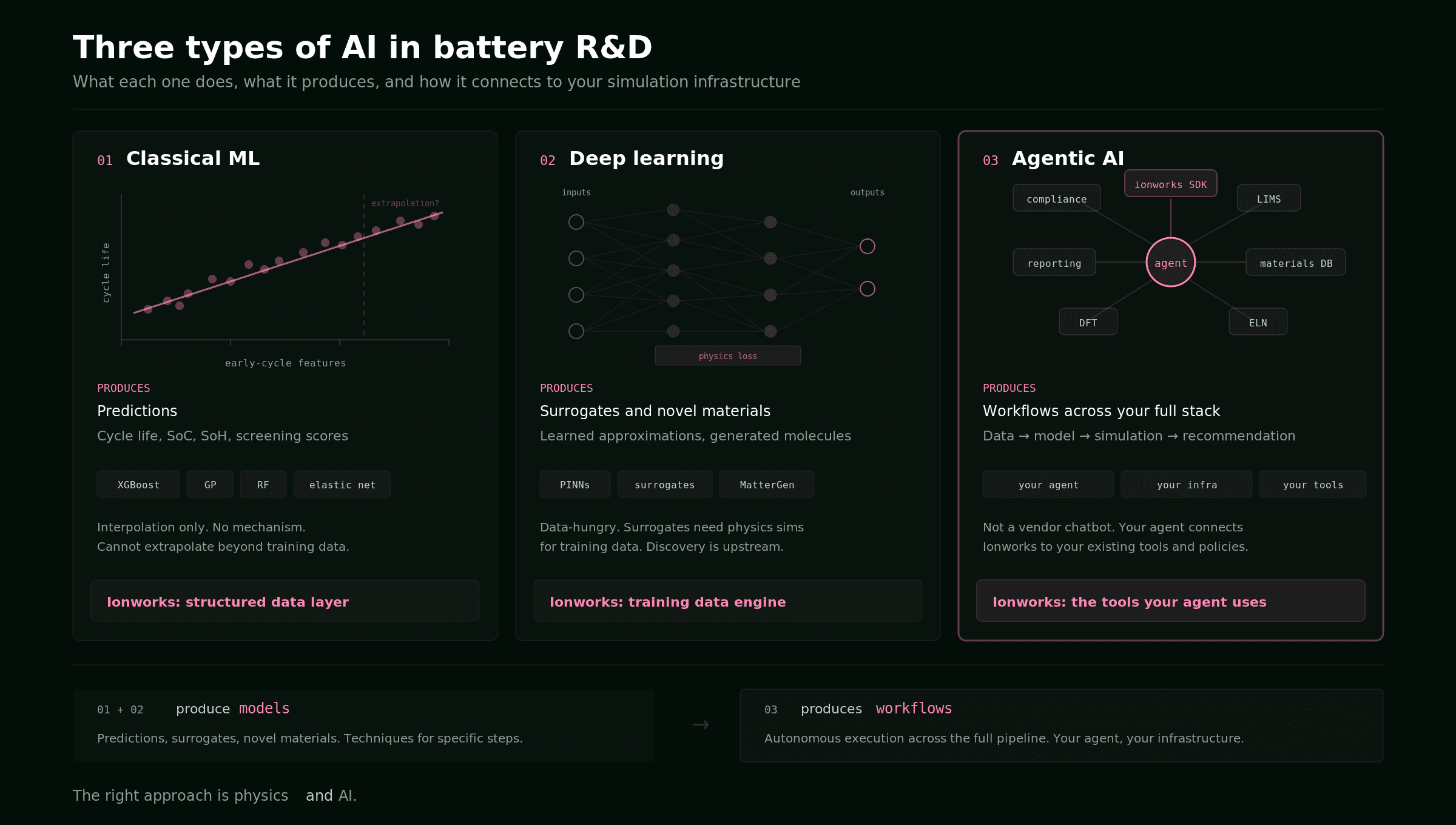
The three categories
The taxonomy is simple.
Classical ML covers the statistical and ensemble methods that have been used in battery science for over a decade: linear and nonlinear regression, Gaussian processes, random forests, gradient-boosted trees (XGBoost, LightGBM). These models learn input-output mappings from tabular data. They are interpretable, fast to train, and work well when you have structured datasets and a clear prediction target.
Deep learning covers neural network architectures: convolutional and recurrent networks, transformers, variational autoencoders, generative models, physics-informed neural networks (PINNs), and learned surrogates. These models handle higher-dimensional inputs (spectra, images, molecular structures, spatiotemporal fields) and can learn representations that classical ML cannot.
Agentic AI covers systems where a large language model has access to tools and can execute multi-step workflows autonomously. An agent does not predict battery properties. It operates software, calls APIs, writes and runs code, interprets results, and decides what to do next. This is the newest category and the least understood.
Each category has a fundamentally different relationship to your simulation and data infrastructure. That relationship determines where Ionworks fits.
Classical ML: known methods, known limitations
The foundational work is Severson et al. (2019, Nature Energy), which showed that cycle life for commercial LFP/graphite cells could be predicted from the first 100 cycles with 9.1% error using features extracted from voltage curves and elastic net regression. The prediction target was clear (cycles to 80% capacity), the features were hand-engineered from domain knowledge (variance of the discharge voltage curve between cycles 10 and 100), and the model was a regularized linear model. Elegant and effective.
Since then, gradient-boosted trees have become the workhorse. XGBoost and LightGBM models predict remaining useful life, state of charge, and state of health from cycling features. Gaussian process regression provides uncertainty estimates for Bayesian optimization of charging protocols. Random forests classify degradation modes from differential voltage analysis. The common thread is tabular data in, scalar prediction out.
What classical ML does well
Screening and triage. If you have 500 cells and need to predict which ones will fail first, a gradient-boosted model trained on early-cycle features will get you there faster than running every cell to end of life. State estimation for BMS applications. Rapid capacity checks. Initial parameter sensitivity ranking before committing to expensive physics-based studies.
Where it struggles
Classical ML models are interpolators. They learn the mapping within your training distribution and have no mechanism to extrapolate beyond it. A cycle life predictor trained on 1C cycling at 25°C tells you nothing useful about 3C at 45°C. Combining datasets from different cell formats, chemistries, and test protocols into a single model is an unsolved problem because there is no shared feature space. Individual datasets are small (tens to hundreds of cells), and the variance between labs is often larger than the signal the model is trying to learn.
The deeper issue is that classical ML models are opaque about mechanism. A model can tell you that cell A will outlast cell B, but not why, and not what design change would close the gap. For R&D teams making design decisions (electrode loading, electrolyte formulation, protocol selection), prediction without mechanism is rarely sufficient.
Where Ionworks fits
Ionworks is not a classical ML tool. But classical ML pipelines depend on clean, structured, well-attributed data, and that data pipeline is exactly what Ionworks Measure provides. Cycling data from Maccor, Neware, BioLogic, Arbin, and Novonix comes in normalized, linked to cell specifications and experimental context, and accessible through a Python SDK that returns DataFrames ready for feature engineering.
For teams that need custom ML models built on top of their Ionworks data, Ionworks custom services engagements deliver trained models integrated into the simulation workflow. The team has built regression and classification models for degradation prediction, state estimation, and screening across multiple customer datasets.
Deep learning: powerful, hungry, and mostly upstream
Deep learning in batteries falls into two distinct camps: surrogate models and molecular or materials discovery.
Surrogates
A surrogate model approximates the input-output behavior of a physics simulation. You run the expensive simulation (say, a DFN model across a grid of electrode thicknesses, porosities, and C-rates) thousands of times, collect the results, and train a neural network to reproduce those results at a fraction of the compute cost. The trained surrogate then replaces the physics model inside an optimization loop or a real-time controller.
This works. Neural ODE surrogates, convolutional networks on spatiotemporal fields, and recurrent architectures on time-series outputs all produce useful approximations when the training set covers the operating domain. The limitation is the same as classical ML, amplified: surrogates are interpolators over the training distribution, and the training distribution is expensive to generate. You need the physics model to build the surrogate, and the surrogate is only as good as the coverage of the training set.
PINNs (physics-informed neural networks) address this partially by encoding conservation laws and boundary conditions into the loss function. A PINN for solid-phase diffusion can satisfy Fick's law by construction, reducing the data requirement and improving extrapolation. The technique is promising but still largely academic for production battery workflows. Training is finicky, convergence is sensitive to the weighting of physics and data terms, and the computational advantage over a well-implemented finite element solver is not always clear.
Molecular and materials discovery
This is where deep learning has produced the most dramatic results in adjacent fields. Microsoft's MatterGen and Google DeepMind's GNoME use generative models and graph neural networks to propose novel inorganic materials and predict their stability. Microsoft partnered with Pacific Northwest National Laboratory to screen 32 million electrolyte candidates, identifying a sodium-lithium mixed conductor (Na_xLi_{3-x}YCl_6) that reduces lithium requirements by roughly 70%. The cycle from computational proposal to lab synthesis took about nine months.
For battery R&D teams, the practical relevance depends on where you sit in the value chain. If your team designs cell chemistries and formulates electrolytes, generative materials discovery is directly relevant (though the tooling is still immature and largely confined to research labs). If your team takes a defined chemistry and optimizes cell design, formation protocols, or degradation management, materials discovery is upstream of your work. Important, but not your bottleneck.
Where Ionworks fits
Ionworks does not ship a deep learning library. The platform's simulation engine is physics-based: SPM, SPMe, DFN, and ECM, solved numerically, not approximated.
But deep learning and physics simulation are complementary. The common pattern is: run thousands of physics simulations in Ionworks to generate labeled training data, then train a surrogate offline. The Ionworks API and Python SDK support this workflow directly. Design parameter sweeps with grid, Latin Hypercube, or Sobol sampling generate the structured simulation results that surrogate training requires. Results come back as DataFrames with full provenance, so the training set is reproducible.
For teams that want to build and deploy surrogates, PINNs, or other deep learning models as part of their simulation workflow, Ionworks custom services engagements provide the integration work. The Python-native interface means deep learning frameworks (PyTorch, JAX) sit alongside Ionworks calls with no adapter layer.
Agentic AI: the one that changes the workflow
The first two categories are techniques. They produce a model (a predictor, a classifier, a surrogate, a generated molecule) that a human engineer then uses. The engineer still decides what to simulate, sets up the runs, interprets the results, and makes the next decision.
Agentic AI is different. An agent is an LLM with access to tools. It receives a goal ("evaluate the impact of electrode thickness on fast-charge capability for this NMC811 cell, subject to a lithium plating constraint"), plans a sequence of actions, and executes them: pull the cell specification from the database, load the parameterized model, configure a thickness sweep with a plating threshold on anode potential, submit the simulations, wait for results, analyze the tradeoff, and return a recommendation with the supporting data.
The distinction matters because it changes who (or what) operates the simulation platform. In the classical and deep learning cases, the platform is a tool used by a human. In the agentic case, the platform is a tool used by another piece of software.
What this looks like in practice
The self-driving laboratory concept is the extreme version. Projects like Coscientist (Carnegie Mellon, 2023) and the MARS multi-agent system have demonstrated LLMs autonomously designing experiments, writing analysis code, controlling robotic instruments, interpreting results, and iterating. These are research demonstrations, not production systems. But the underlying architecture, an LLM that calls tools through structured APIs, is mature and deployable today for simulation workflows that don't involve physical lab equipment.
A more grounded example: an AI coding assistant (Claude Code, a custom agent pipeline, or a script using the Anthropic or OpenAI APIs) connects to the Ionworks Python SDK. The agent can:
- Query the measurement database for cycling data matching specific criteria
- Load or create a parameterized model for a given cell specification
- Configure a simulation with a protocol and design parameter sweep
- Submit the simulation batch and poll for results
- Analyze the results against engineering constraints
- Generate a summary with plots and recommendations
- File the results in a study for the team to review
Each step is an API call. The agent makes the decisions between steps: which model to use, how to set up the sweep, what constraints to check, how to interpret the tradeoff. A human reviews the output, but the workflow execution is autonomous.
Why "your agent" matters more than "our chatbot"
Several simulation vendors now offer chat interfaces where you can ask questions about your data or have an assistant help configure a simulation. That is useful as a productivity feature. But it is the vendor's AI, running inside the vendor's UI, with access only to the vendor's tools. You cannot connect it to your internal databases, your LIMS, your compliance checks, or your reporting pipelines. You cannot control its safety policies or audit its behavior. And when the vendor decides what the chatbot can and cannot do, you are stuck with those decisions.
The more interesting question is: what if battery simulation is a skill your agent already has?
Most R&D teams building with AI are converging on an agent they control. It runs on their infrastructure (or through a provider they have evaluated). It connects to their internal tools: ELN, LIMS, materials databases, test scheduling systems, maybe DFT codes. It follows their safety and access policies. The team has validated it, audited it, and integrated it into their existing workflows.
That agent needs to be able to call a battery simulation platform the same way it calls everything else. It calls ionworks.CellSpecification.get(), then ionworks.ParameterizedModel.get(), then ionworks.Simulation.create(), then reads the results and checks anode_potential.min() > 0. It does not need a separate browser tab, a separate login, or a separate AI system. It needs structured tool definitions, typed inputs and outputs, and a programmatic interface that works without a GUI.
This is the architectural bet Ionworks made. The platform is API-first: every capability available in the browser, from data ingestion through parameterization, simulation, optimization, and result export, is available through the REST API and Python SDK. An agent built on Claude Code, a custom pipeline using the Anthropic or OpenAI APIs, a scheduled job in a CI system: all of them connect through the same interface a human engineer uses. There is no separate "AI mode" and no adapter layer.
Skills, not just endpoints
Connecting an LLM to a raw REST API is possible but fragile. The agent needs to know which endpoints exist, what parameters they accept, what the responses look like, and what sequences of calls constitute valid workflows.
Ionworks provides structured tool definitions and skills that give agents this context: what operations are available, how to compose them, and what engineering constraints to check. An agent with Ionworks skills can discover capabilities through a /discovery endpoint, build valid workflows without hard-coding API paths, and operate the platform the way an experienced battery engineer would.
Skills are portable. They plug into whatever agent framework the team is already using. The team does not adopt a new AI system to get battery simulation. They give their existing agent a new capability.
Composability over containment
The practical consequence of this architecture: battery simulation becomes one tool in a larger autonomous workflow.
An agent that can call the Ionworks API can also query a materials property database, run a DFT calculation, check a lab scheduling system, pull data from a LIMS, and file results in a team wiki. The simulation step fits into a chain the team controls end to end. Contrast this with a vendor chatbot that lives inside a single application. That chatbot can answer questions about the data inside the application. It cannot reach out to the team's other systems, and external systems cannot reach in. Every integration requires the vendor to build it.
The difference compounds. A team with a composable agent adds tools incrementally: connect Ionworks this quarter, add the materials database next quarter, hook up the ELN after that. Each new connection makes the agent more capable across the full R&D workflow. A team locked into vendor-specific chat UIs has a separate AI assistant in each application, none of which talk to each other.
Where each type fits in the R&D workflow
The three types of AI occupy different positions in the battery development process, and their value depends on what question you are trying to answer.
Screening and triage (is this cell worth investigating further?) is well served by classical ML. XGBoost on early-cycle features, Gaussian processes for Bayesian optimization of test protocols. The data requirements are modest and the prediction targets are clear.
Design space exploration (what electrode geometry, electrolyte formulation, or protocol minimizes charge time subject to degradation constraints?) is where physics simulation lives, and where agentic AI amplifies throughput. An agent can set up, run, and analyze hundreds of simulation studies that would take an engineer weeks to configure manually.
Materials discovery (what novel cathode or electrolyte composition should we synthesize next?) is deep learning territory. Generative models and graph neural networks operating on molecular and crystal structures. This work is mostly upstream of cell-level simulation and largely confined to materials research groups.
Deployment and controls (real-time state estimation, thermal management, charge optimization on embedded hardware) is classical ML and ECMs. The models need to be fast and small, not physics-rich.
The pattern: classical ML and deep learning produce models. Agentic AI produces workflows. The former are techniques you integrate into specific steps. The latter is an approach to how work gets done across the entire pipeline.
Where Ionworks sits
Ionworks is built for the third category. The platform is AI-native: designed from the start so that agents and engineers use the same interface. The API-first architecture, structured tool definitions, and Python SDK are the infrastructure that makes agentic simulation workflows possible.
For classical ML: Ionworks provides the structured data layer. Clean, normalized, well-attributed cycling data from all major cycler formats, accessible through a Python SDK that feeds directly into ML pipelines. No more weeks of data wrangling before the modeling can start.
For deep learning: Ionworks provides the simulation engine that generates training data for surrogates and the programmatic interface that deep learning frameworks integrate with natively. Design parameter sweeps with Sobol and Latin Hypercube sampling produce the structured datasets that surrogate training requires.
For agentic AI: Ionworks provides the tools. The REST API, the Python SDK, the structured skills, and the /discovery endpoint are what allow an external agent to operate the full Simulation OS workflow autonomously. This is not a chat window bolted onto a GUI. It is a simulation platform built to be operated by software as effectively as by a person.
Custom services engagements extend this further. For teams that need classical ML models (degradation predictors, state estimators, screening classifiers) or deep learning models (surrogates, PINNs) integrated into their Ionworks workflow, the team delivers these as part of a consulting engagement. The models ship as Python artifacts that plug into the same data and simulation infrastructure.
The right approach is physics and AI. Not physics or AI. And "AI" means something specific depending on what engineering problem you are solving.
Frequently asked questions
Continue reading