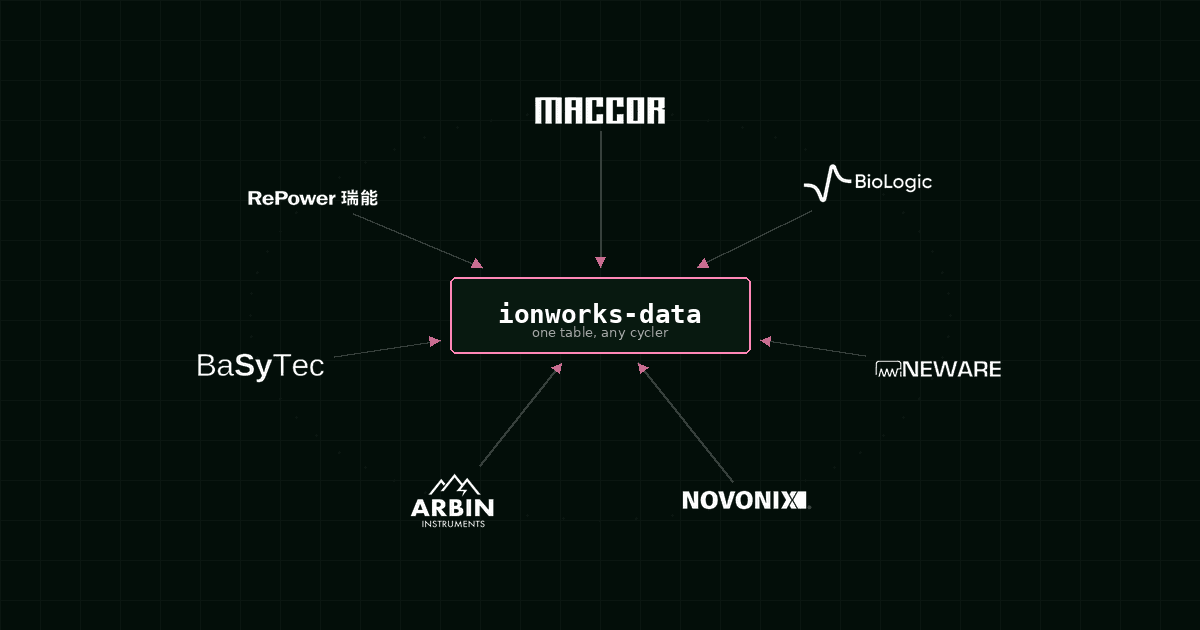
We are open-sourcing ionworks-data, a Python library that reads battery cycling data from different cycler formats and writes it into a single consistent table. It supports Maccor, BioLogic, Neware, Novonix, BaSyTec, Repower, Gamry, generic CSV, and the Battery Data Format (BDF). The output is a Polars DataFrame with fixed column names, fixed units, and a fixed current sign convention.
There is no shortage of libraries that do this. We are aware of the xkcd. We are not proposing a new standard, and if you are looking for one, the Battery Data Format (BDF) from the Battery Data Alliance is the one the industry seems to be converging on (ionworks-data reads and writes it). We built this because we needed it internally, we have been maintaining it for a while, and we figured it might save someone else some time.
The problem, briefly
Every cycler vendor has its own file format, its own column naming, its own unit conventions, and its own ideas about whether discharge current should be positive or negative. Maccor ships tab-delimited text with thousands separators in the numbers. BioLogic .mpr files are binary. Neware sometimes puts multiple datasets across Excel sheets. Novonix has a [Summary] section before the time series starts. We have written before about how battery workflows break at the handoffs between tools and teams. Data format fragmentation is one of the earliest handoffs, and one of the most annoying.
If your lab runs two brands of cycler, you already have a harmonization problem. If your data comes from a partner, a supplier, or an acquisition, you have a worse one.
What ionworks-data does
The library reads a file, detects the format (or accepts a hint), and produces a DataFrame with these columns:
Time [s], Current [A], Voltage [V], Step count, Cycle count, Discharge capacity [A.h], Charge capacity [A.h], Discharge energy [W.h], Charge energy [W.h]
Optional columns for temperature, impedance (Z_Re, Z_Im, frequency), and cycler-provided step or cycle labels are included when the source file has them. Anything the library does not recognize is passed through as-is.
Current is always discharge-positive, charge-negative. Time is always in seconds, starting at zero. Capacity and energy are cumulative and computed from the current and voltage traces if the source file does not already provide them.
That is the whole contract. Read a file, get a table, know what the columns mean.
Readers
Each cycler format has a dedicated reader that handles the specific quirks of that format.
Maccor strips thousands separators, handles both tab and comma delimiters, and deals with multiple file encodings. BioLogic reads both the text .mpt format and the binary .mpr format, including impedance data from EIS experiments. Neware handles multi-sheet Excel files and falls back to Latin-1 encoding when UTF-8 fails. Novonix skips the summary header and reads the time series. Gamry parses .dta files and extracts impedance tables.
There is also a generic CSV reader for files that use recognizable column names, and a BDF reader and writer. If you want to convert your existing data into BDF for archival or sharing, ionworks-data can do that too.
Auto-detection works in most cases. If it does not, you pass the cycler name as a string.
import ionworksdata as iwdata
# auto-detect
data = iwdata.read.time_series("my_file.mpt")
# explicit
data = iwdata.read.time_series("my_file.csv", "maccor")
Transforms
Beyond reading, the library provides transforms for capacity integration, energy calculation, step counting, cycle counting, and current sign normalization. These run automatically during a standard read, but they are also available individually if you want to apply them to data you loaded some other way.
Impedance data
For EIS experiments, the library reads frequency and complex impedance from BioLogic and Gamry files. If the source provides modulus and phase but not real and imaginary parts (or vice versa), it derives the missing components. The output columns are Frequency [Hz], Z_Re [Ohm], Z_Im [Ohm], Z_Mod [Ohm], and Z_Phase [deg]. This is the same impedance data you would use for ACIR and DCIR analysis or ECM fitting.
Design choices
A few decisions worth noting.
The library uses Polars rather than pandas. Polars is faster for the column-oriented operations that dominate here, and it avoids the index-alignment surprises that trip people up in pandas. If you need a pandas DataFrame, .to_pandas() is one call away.
Column names include units: Current [A], not Current or I_A. This is slightly verbose but eliminates an entire class of "wait, is this in milliamps?" questions.
Unknown columns are passed through. If the cycler file has a column the library does not recognize, it stays in the output DataFrame untouched. Nothing is silently dropped.
What else is out there
Battery data harmonization is a well-trodden problem and there are several other open-source projects in the space. We built ionworks-data because none of them were quite the shape we needed for ingestion into Ionworks Measure, but if you are evaluating options, the rest of the landscape is worth knowing.
BEEP, the Battery Evaluation and Early Prediction toolkit from Toyota Research Institute, parses Arbin, BioLogic, Maccor, and Neware files into a structured form, with a heavier emphasis on featurization for early-life cycle prediction. It is the project most often cited alongside the Severson et al. dataset.
BattETL, from BattGenie, focuses on Maccor and Arbin and writes into a Postgres schema. The framing is closer to a classical extract-transform-load pipeline than a DataFrame library; it is the right shape if you want a database from the start.
PyProBE, from the Imperial College London battery group, is a Python library for processing and exploring battery data with readers for several cycler formats and built-in analysis methods. It is closer in shape to ionworks-data than the database-flavoured projects, with more emphasis on interactive analysis.
Galvanalyser, from the Howey group at Oxford, is a long-running web-app and database for academic battery test management with parsers for several cycler formats. It targets a research-group workflow rather than a notebook user.
For the standard itself, the Battery Data Format (BDF) from the Battery Data Alliance is the cross-industry effort to converge on a single schema. ionworks-data reads and writes BDF, and most of these projects either export to it or are working towards it.
If your problem is "I need a clean table in a notebook from this .mpt file", ionworks-data is probably the lightest path.
Why we are releasing this
We use ionworks-data as the data ingestion layer for Ionworks Measure, our data management platform. Every file uploaded to Measure runs through this library before it reaches the database. It has been tested against a wide range of real files from real labs, and we fix edge cases as we find them.
Open-sourcing the harmonization layer separately means you do not need an Ionworks account to use it. If all you need is to get your Maccor and BioLogic data into the same format for a Jupyter notebook, this does that.
Install from PyPI:
pip install ionworksdata
The source is on GitHub. If you run into a format we do not handle or an edge case that breaks, open an issue on GitHub.
Using it from a coding agent
A growing number of teams point a coding agent (Claude Code, Cursor, the Anthropic Agent SDK) at a folder of cycler files and ask it to "get this into a usable format." Without context, the agent guesses. It picks pandas, invents column names, gets the discharge sign wrong, resets time at every cycle, and writes a 200-line parser when one library call would have done it.
So we also released a process-data skill in ionworks-skills, our open-source toolkit of Anthropic-style skills for battery R&D workflows. The skill is a single Markdown file the agent loads when it sees raw cycling data. It tells the agent which ionworksdata reader to call, how to handle the cumulative-time and cumulative-step pitfalls, when to use set_capacity and set_energy, and how to write either the parquet + JSON bundle (for the platform) or a single .bdf file (for sharing or archival).
In Claude Code, it installs as a plugin:
/plugin marketplace add ionworks/ionworks-skills
/plugin install ionworks
For other Anthropic SDK agents, the SKILL.md files are plain Markdown. Load them with the Skill tool or copy them into your agent's skills directory.
process-data is the data layer of the toolkit and runs against open-source ionworksdata alone, no Ionworks account needed. The platform layer (uploading measurements, managing cells, running simulations, organizing projects) drives the Ionworks Python SDK against the Ionworks platform and needs an account.
The skill and the library are deliberately split. ionworksdata is the engine: deterministic, importable from any Python script, no agent required. The skill is the operating manual that lets an agent drive the engine without hallucinating around the conventions.
When you need more than a DataFrame
ionworks-data gives you clean, consistent tables. It does not store them, version them, or link them to anything.
Ionworks Measure does. Measure stores cycling data and metadata in a structured database organized around cells, measurements, and experimental context. Every measurement links to its cell specification, its test protocol, and its operating conditions. When you are ready to run simulations, that structure is what makes it possible to pull the right data for parameterization without hunting through folders and filenames.
If you are working in a notebook and a DataFrame is all you need, ionworks-data is the right tool. If your team is generating data that needs to stay organized and eventually connect to models, Measure is worth a look.
We also offer an optional validation layer through the Ionworks Python API. When you upload data through the API, it runs additional checks on top of what ionworks-data provides to make sure everything reaching the platform is clean and correctly structured. More on that in a future post.
Continue reading